
그래프코어가 지능형 처리 장치인 IPU-POD64 시스템에 대한 첫 번째 MLPerf 벤치마크 결과를 공개했다. 이번 벤치마크에서 IPU-POD64는 BERT 학습 시간에서 9분, ResNet-50 학습 시간에서 14.5분을 기록했다. 이는 슈퍼컴퓨터에 버금가는 성능으로, 경쟁사와 대비할 때 달러당 성능 지표에서 확고한 우위를 선점한 것이라고 그래프코어는 밝혔다.
컴퓨팅 시스템의 성능은 단순하게 하드웨어의 기계적인 사양만으로는 성능을 객관적으로 평가하기 힘들다. 그래서 필요한 것이 주로 사용하는 용도와 목적에 맞도록 설계된 벤치마크 프로그램이다. 최근 들어 인공지능 처리능력을 극대화한 GPU, IPU 등의 사용 범위와 규모가 커지면서, 이들 시스템이나 플랫폼의 성능을 테스트하는 MLPerf와 같은 벤치마크에 대한 활용 범위도 갈수록 커지고 있다.
MLPerf는 인공지능 관련 성능을 테스트할 수 있는 벤치마크로, MLPerf 트레이닝(Training)과 MLPerf 인퍼런스(Inference)가 있다. MLPerf 트레이닝은 컴퓨터 비전, 강화학습, 언어 등의 활용 사례를 포함하는 8가지 워크로드로 구성되어 있다. MLPerf 인퍼런스는 7가지의 뉴럴 네트워크 테스트로 구성되어 있으며, 컴퓨터 비전, 언어 처리, 메디컬 이미징 등에 대한 테스트를 수행한다.
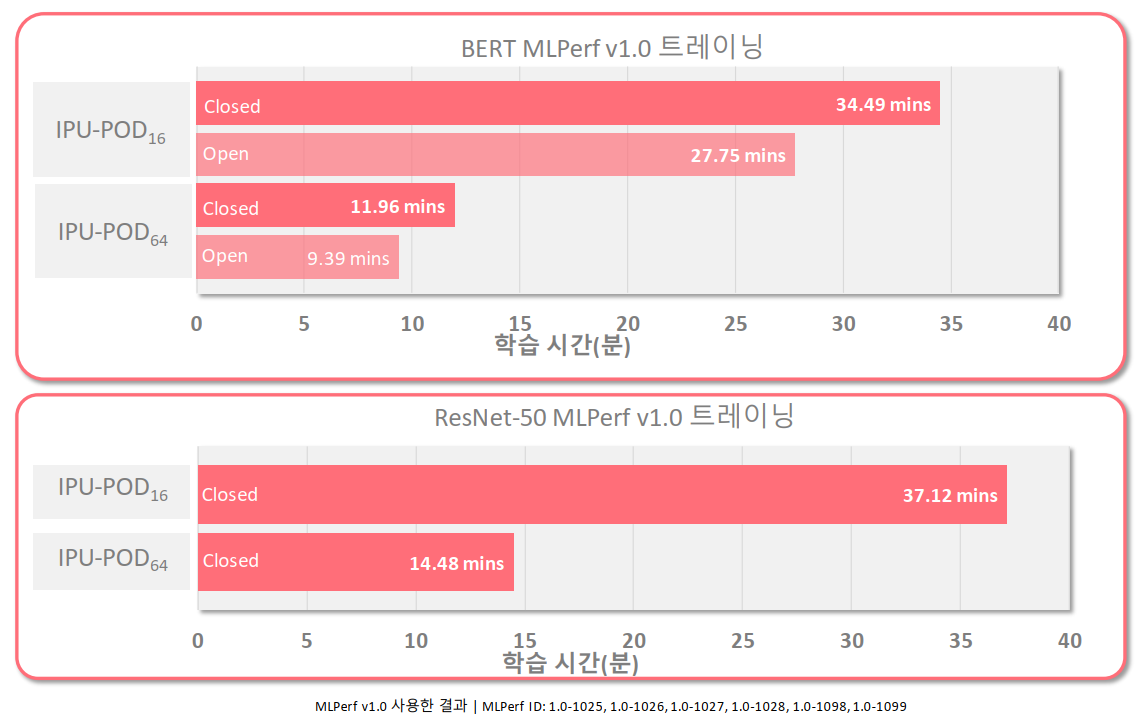
그래프코어가 자사의 IPU-POD16과 IPU-POD64에 대한 MLPerf의 자연어 처리와 이미지 분류 성능 벤치마크 결과를 공개했다. 그래프코어는 IPU-POD16의 벤치마크 결과, ResNet-50학습에서 경쟁사 대비 1.6배, BERT에서는 경쟁사 대비 1.3배 향상된 성능을 구현했다고 밝혔다. (자료:Graphcore)
이번에 그래프코어가 공개한 MLPerf 테스트 항목은 MLPerf 트레이닝으로 자연어 처리(NLP[BERT])와 이미지 분류인 ResNet-50 항목에 대해서만 벤치마크를 진행한 결과다. 그래프코어는 이런 결과를 기준으로 IPU-POD16이, ResNet-50학습에서 경쟁사 대비 1.6배, BERT에서는 경쟁사 대비 1.3배 향상된 성능을 구현했다고 강조했다.
그래프코어는 소프트웨어 스택 포플러 SDK(Poplar SDK)의 꾸준한 업그레이드가 이번 벤치마크에서 좋은 결과를 내는 데 중요한 역할을 했다고 전했다. 그동안 포플러 SDK는 2020년 12월부터 2021년 6월까지 6개월 동안 3번의 업데이트를 거치며, ResNet-50에서 2.1배, BERT-Large에서 1.6배, ResNet보다 훨씬 높은 정확도에 초점을 맞춘 컴퓨터 비전 모델인 에피션트넷(EfficientNet)에서는 1.5배 향상된 성능을 선보였다.
강민우 그래프코어 한국 지사장은 “이번 테스트에 적용된 개선 및 최적화 사항이 이미 소프트웨어 스택에 모두 업데이트되었고, 전 세계 그래프코어 사용자들은 BERT와ResNet-50을 포함, 다양한 모델에서 그래프코어 MLPerf 제출의 이점을 누리고 있다”며, “그래프코어는 앞으로도 MLPerf의 학습 및 추론 라운드에 지속해서 참여하며 성능 향상, 스케일 향상, 모델 추가라는 세 가지 목표를 달성하기 위해 노력할 계획”이라고 말했다.

7nm 공정을 적용한 그래프코어의 콜로서스(Colossus) MK2 GC200 IPU, 1,472개의 프로세서 코어로 구성되며, 9,000개의 독립적인 스레드를 실행한다. (사진:Graphcore)
영국에 본사를 둔 그래프코어는 2012년 설립된 인공지능 반도체 및 시스템 전문기업이다. 반도체 기반의 지능형처리장치인 IPU(Intelligence Processing Unit) 프로세서와 제품을 개발 및 제조하고 있다. 현재 IPU-M2000, IPU-POD16, IPU-POD64, 그래프클라우드(Graphcloud) 등의 제품으로 라인업을 구성하고 있다.
콜로서스 GC200 IPU 4개로 가동되는 IPU-M2000은 1U 블레이드에 1페타플롭 AI 연산 성능을 탑재했다. 대규모 배치를 위한 그래프코어의 IPU-POD64는 최대 64개의 IPU 프로세서 병렬 처리로 대규모 모델 연산을 처리할 수 있으며, 다수의 사용자와 태스크 간에 컴퓨팅 리소스를 공유할 수 있다. 엑사스케일 컴퓨팅의 경우, IPU-POD 구성으로 최대 6만 4천 개의 IPU를 연결해 사용할 수 있다.
'🅣•TREND•TECHNOLOGY > ARTIFICIAL INTELLIGENCE' 카테고리의 다른 글
| 사람 말귀 더 잘 알아듣는 AI...오픈AI, 다국어 음성 인식 '위스퍼' 아키텍처 공개 (0) | 2022.09.23 |
|---|---|
| 직접 만든 콘텐츠에 AI 성우 목소리를...머프, 사람만큼 자연스러운 AI 음성 라이브러리 (0) | 2022.09.22 |
| 아바타 제작도 클라우드 AI로 간편하게...엔비디아, '옴니버스 ACE' 발표 (0) | 2022.08.11 |
| 100만 명에게 AI 이미지 생성 제공...오픈AI, DALL·E 2 베타 출시 (0) | 2022.07.23 |
| AI로 정확하고 빠르게 제품 결함 콕 집어낸다...구글, '시각 검사 AI 솔루션' 발표 (0) | 2021.06.23 |
| AI가 도로 위 포트홀 찾는다...구글, ML활용 도로 보수 사례 공개 (0) | 2021.01.14 |
| 도시 나무 심기에 AI와 항공 사진 활용...구글, 열섬 현상 해결하는 '트리 캐노피 랩' (0) | 2020.11.19 |
| 실시간 3D 감지 모델과 벤치마크 지원...구글, '오브젝트론 데이터 세트' 출시 (0) | 2020.11.11 |



