
소식이나 기술로 접하는 인공지능은 '나'와 조금은 동떨어져 보이지만, 실생활 속에 인공지능은 이미 '나'의 삶 곳곳에 자리를 잡고 있다. 인터넷 포털 속에서 제공하는 수 많은 정보나 검색 엔진부터 메신저, 스트리밍, 게임, 음성 비서, 사진이나 동영상 앱 등 이미 수 많은 곳에서 인공지능이 활약하고 있다.
하지만 지금까지의 인공지능은 인간의 감각이나 능력 중에서 어느 한 가지에 초점을 맞춰 특화 시킨 것이 대부분이다. 예를 들어 문자와 문장을 인식하고 분석해 검색이나 번역에 활용하고, 음성으로 정보를 주고 받는 음성 기반 인공지능 비서, 영상이나 동영상 속의 사물이나 문자를 인식하고 구분하는 것이 그렇다.
| 텍스트-이미지 또는 언어-이미지 등 여러 채널로 상호작용하는 멀티모달 AI
컴퓨터, 스마트폰, 태블릿, 키오스크, 로봇, 음성 비서 등 컴퓨팅 장치와 사람이 서로 상호작용(Interaction)하려면, 양쪽이 모두 인식할 수 있는 형태나 형식의 정보를 사용해야 한다. 즉, 사람과 사람이 문자, 문서, 언어, 표정, 손짓, 몸짓, 사진, 그림, 영상 등으로 활용해 소통하는 것처럼, 사람과 컴퓨팅 장치도 그렇게 소통할 수 있는 의사 소통 채널이 필요하다.
이러한 형식이나 형태를 갖춘 의사 소통 채널을 모달리티(Modality)라고 하고, 두 가지 이상 여러 개의 모달리티를 활용하면 멀티모달리티(MultiModality)라고 한다. 멀티모달은 이를 줄여서 부르는 말로, '멀티모달 AI'는 여러 가지 형식의 데이터나 소통 채널을 활용하는 인공지능이라는 의미다.
예를 들어 문자나 단어로 된 키워드를 입력해서 원하는 정보를 찾을 수 있는 검색 엔진에 사용된 인공지능이 싱글모달이라고 하면, 문장이나 문서로 설명한 정보를 기반으로 그림이나 사진을 찾거나, 음성으로 입력한 정보를 기반으로 동영상을 찾는 것처럼, 두 가지 이상의 정보를 활용하는 것이 바로 멀티모달 인공지능이다.
일상이나 업무에서 활용되고 있는 대부분의 인공지능은 지금까지 한 가지 입력 채널을 사용하는 싱글모달 AI가 대부분이다. 앞에서 얘기한 문자 기반의 검색 엔진이나 번역기, 음성만으로 정보를 주고 받는 인공지능 스피커, 사진이나 영상에서 원하는 객체를 찾아주는 컴퓨터 비전 기술 등이 그렇다.
하지만 이러한 요소들을 두 가지 이상 결합한 멀티모달 AI로 인공지능이 진화를 거듭하면서, 새로운 인공지능 기술을 활용한 새로운 세상이 열리고 있다. 기존의 싱글모달 AI가 한 가지 기능을 특화해 사람을 흉내내는 '인공지능'이었다면, 멀티모달 AI는 거의 사람과 동일 수준의 능력을 갖는 '복합지능'을 지향하고 있다.
| 멀티모달 AI에서는 1+1=2가 아니라, 더 다양한 답과 길이 있다
펜데믹으로 '비대면'이 익숙한 세상을 갑자기 살게 되면서, 만나서 얼굴 보고 대화하지 않고 소통하는 것에 많은 사람들이 익숙해졌다. SMS나 메신저, 이메일, 음성 통화 등 이미 이전부터 커뮤니케이션 수단으로 활용하던 것에, 여러 명이 참여하는 음성이나 화상 회의 그리고 채팅까지 소통 채널이 다양해 졌다. 하지만 아무리 좋은 기술과 장비를 사용해도, 직접 만나 얼굴을 마주하고 대화하는 것 만큼 확실한 것은 없다.
인공지능을 활용하는 경우도 만찬가지다. 하나의 채널만을 사용하면 입력할 수 있는 데이터나 얻을 수 있는 정보에 제한을 받을 수밖에 없다. SMS나 메신저로 전달하는 '문장'만으로는, '음성'과 얼굴 '표정'에 담긴 감정이나 느낌까지 전달할 수 없는 것과 같다. 그래서 더 많은 형태의 정보를 주고 받을 수 있는 멀티모달 AI는 그 만큼 사람과의 소통이 정확하고 풍부해질 수 있다.
문자+음성, 음성+표정, 표정+손짓, 손짓+몸짓, 문장+사진, 음성+영상 등 두 가지 형태의 정보 채널만 조합해도 전혀 다른 인공지능을 생활과 업무에서 만날 수 있다. 이러한 멀티모달 AI에 대한 연구와 시도는 문자 위주에서 음성, 사진, 영상 등과 결합하는 단계로 발전하고 있으며, 계속해서 더 많은 소통 채널을 결합한 멀티채널 AI 계속해서 진화중이다.
이러한 진화를 통해 궁극적으로 두 가지 이상의 소통 채널이 아니라, 세 가지 또는 네 가지 이상의 소통 채널을 인공지능과 사람이 활용할 수 있게 되는 것이 멀티모달 AI가 지향하는 목표다. 문자+문장+음성+언어+표정+손짓+몸짓+사진+영상 등 이러한 모든 요소를 소통 채널로 활용할 수 있게 되면, 디지털 휴먼이나 휴머노이드 거의 실제와 구분하기 힘들 정도로 정교하고 사실적으로 구현하는 것이 가능해진다.
이를 테면 검색 엔진만 보더라도 초기의 검색엔진은 데이터 베이스에서 키워드와 일치하는 항목을 찾아서 보여주는 초보적인 수준에 불과했다. 하지만 검색엔진에 인공지능을 도입해 자연어를 이해할수 있는 알고리즘과 학습 기능이 적용되면서, 검색할 수 있는 영역과 정확성이 몰라보게 향상됐다.
하지만 문자나 문장만을 사용한 검색은 한계가 있을 수밖에 없다. 사람은 보고, 듣고, 말하고, 쓰는 다양한 감각 및 행동으로 소통하기 때문이다. 따라서 이미지나 영상 형태로 된 정보를 검색하려면, 인공지능도 사진이나 영상 속의 객체나 배경을 분석하고 이해할 수 있어야 한다.
사진을 제시하거나 선택하면 비슷하거나 관련성 있는 정보를 찾아주는 이미지 검색 기능이 제공되면서, 이제 검색 기능을 활용해 원하는 정보를 찾는 것이 훨씬 수월해졌다. 스마트폰 앱이나 인터넷 쇼핑몰에서 비슷한 무늬나 디자인의 옷이나 신발 검색이 가능해진 것도 멀티모달 AI 덕분이다.
| 컴퓨팅 장치와 사람을 이어주는 모달리티, 다양해지는 만큼 재주와 능력도 늘어난다
최근 들어 인공지능으로 구현한 재주와 능력이 일취월장하면서 사람의 흉내를 내는 수준을 넘어 사람의 고유영역에 까지 도전하며 다양한 분야로 활동 범위가 넓어지고 있다. 소설이나 영화 속의 바로 그 상상이나 이야기가 이미 현실이 되고 있는 것이다. 우리가 생각하지도 못하고 알지도 못하는 사이에 그런 일이 일어나고 있다.
이미 우리는 일상 속에서 두 가지 이상의 소통 채널을 활용하는 멀티모달 AI를 활용하고 있다. 구글의 '구글 렌즈(Google Lens)'나 네이버의 '스마트 렌즈(Smart Lens)가 그런 것들이다. 두 가지 모두 사진을 기반으로 비슷한 사진을 검색하거나 사진 속에 담겨진 텍스트를 인식하고 추출하는 등의 용도로 사용된다.
쉽게 말하면 스마트폰 카메라로 촬영한 사진을 입력 데이터로 활용해, 비슷한 느낌이나 패턴의 사진을 찾고, 사진 속에 포함된 문자나 문장 등을 추출하고 이해할 수 있다. 구글 렌즈는 사진 속에 있는 텍스트를 인식하고 추출할 수 있기 때문에 이를 복사해서 다른 곳에 붙여 넣을 수도 있고, 실시간으로 번역도 가능하다. 스마트폰에 구글 렌즈만 설치하면 다른 나라 언어로 작성된 간판, 도로 표지판, 문서 등을 이해하는 것도 문제가 없다.

오픈 AI에서 개발한 달·이(DALL·E)나 구글의 이매젠(Imagen)은 구글 렌즈나 스마트 렌즈와는 조금 다르게 텍스트를 기반으로 이미지를 생성하는 인공지능이다. 2021년 세상에 선보인 오픈AI의 달·이(DALL·E)는 1세대 버전을 거쳐 2022년 1월에 2세대 버전인 달·이 2(DALL·E 2)를 공개했다. 달·이와 이매젠은 텍스트와 사진이라는 두 가지 형식을 융합한 대표적인 멀티모달 AI로 꼽을 수 있다.
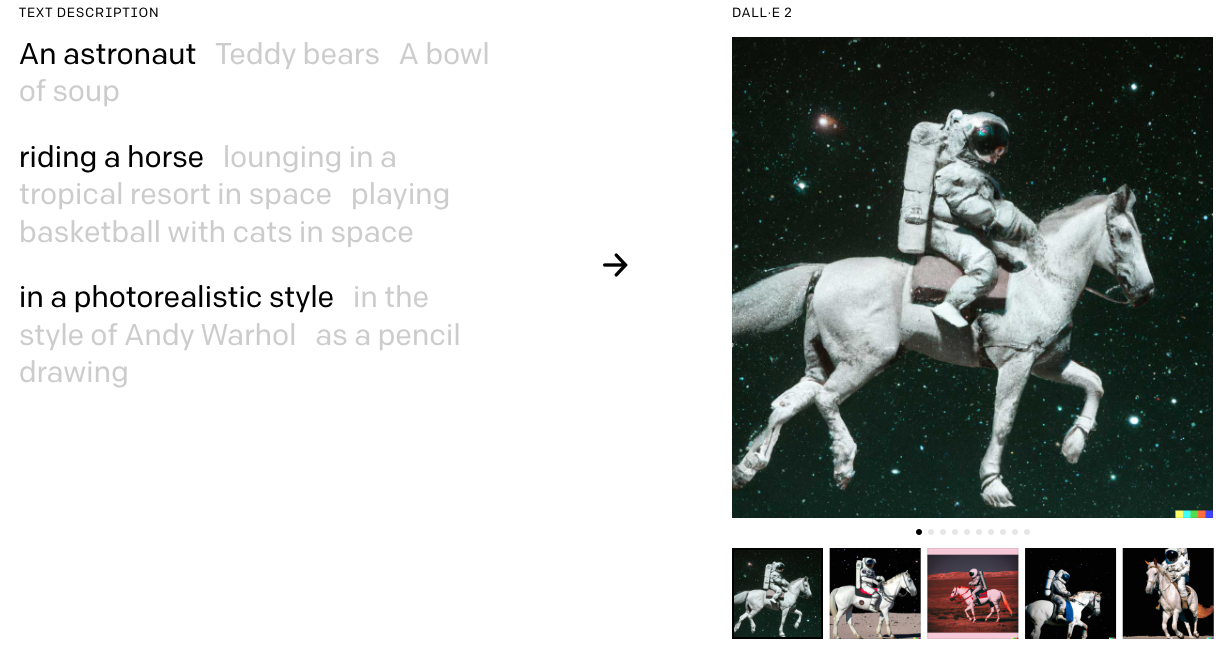
달·이 2에서 '말을 타고 있는 우주 비행사'라고 문자로 입력하면, 실제로 말을 타고 있는 우주 비행사의 모습이 담긴 사진을 만들 수 있다. 이렇게 생성한 사진은 편집, 변형이 가능하고, 누구나 자유롭게 사용할 수 있다. 달·이 2는 현재 베타서비스 기간으로 사용을 하려면 먼저 대기자 명단에 등록을 해야한다. 등록 후 초대장을 받으면 실제로 인공지능을 활용한 이미지 서비스를 활용할 수 있다.
구글의 이매진(Imagen)도 달·이처럼 입력된 텍스트를 기반으로 이미지를 생성하는 기본적인 구조는 동일하다. 달·이와 마찬가지로 '초밥으로 만든 집에 살고 있는 귀여운 코기(A cute corgi lives in a house made out of sushi)'처럼 현실에서는 보기 힘든 장면을 묘사해도 바로 사진으로 만들어 준다.

달·이와 이매진은 기능적으로 보면 동일한 인공 지능 같지만 인공 지능을 학습 시키고 작업을 수행하는 알고리즘에는 차이가 있다. 최근들어 달·이와 이매진처럼 텍스트를 기반으로 이미지를 생성하는 다양한 인공 지능이 개발되고 있고, 이를 활용해 만든 이미지를 다양한 분야에서 사용하는 것은 물론이고, 예술적 창작 활동에 활용하는 경우도 등장하고 있다.
이렇게 인공 지능이 다양한 형태의 정보를 복합적으로 활용하며 사람에 좀 더 가까워지면서, 'AI 아티스트'나 'AI 휴먼'이라고 스스로를 규정한 다양한 형태의 인공 지능이 출현하고 있다. 이렇게 세상에 등장한 인공 지능을 기반으로 한 가상 인간이나 예술가는 다양한 상대와 협업을 진행하며 활동 범위를 넓혀 가고 있다.
카카오 브레인이이 AI 아티스트로 공개한 ‘카를로(Karlo)’는 특정 키워드와 화풍을 입력하면 맥락을 이해하고 그에 맞는 이미지를 생성하는데, 최근에는 현대미술가와 협업을 통해 '알고리즘'이라는 작품을 선보였다. 마이크로소프트가 선보인 넥스트 렘브란트(The Next Rembrandt)는 네덜란드의 화가였던 '렘브란트 반 레인'의 화풍을 모방한 이미지를 만들어 준다.

LG가 2022년 2월에 공개한 AI 기반 아티스트인 '틸다(Tilda)'는 이러한 멀티모달 AI가 앞으로 얼마나 발전하고 활약할 수 있는지를 보여주는 대표적인 사례다. 틸다는 LG가 개발한 초거대 AI인 ‘엑사원(EXAONE)’으로 구현한 첫 번째 AI 휴먼이다. 오픈 AI의 달·이와 구글의 이매진은 영어만을 학습하고 이해하지만, 엑사원은 원어민 수준의 한국어와 영어를 구사하는 이중 언어 AI다.
더구나 텍스트, 음성, 이미지, 영상을 자유롭게 활용할 수 있는 멀티모달 AI라고 할 수 있다. 틸다는 이러한 엑사원의 능력을 팬션에 초점을 맞춰 개발한 AI 휴먼으로, 스스로 학습하고 사고하며 판단하면서 언어의 맥락을 이해한 후 이를 기반으로 이미지를 창작한다. 이러한 능력을 바탕으로 앞으로 틸다는 패션과 미술 분야에서 활약하며, 메타버스에서 Z 세대와 소통할 예정이다.
틸다와 디자이너의 협업으로 탄생한 의상들이 2022년 2월 14일 뉴옥에서 열린 '2022 F/W 뉴욕 패션 위크'에서 선보이기도 했다. 디자이너가 틸다에게 '금성에 꽂이 피면 어떤 모습일까?'라는 질문을 하고, 이를 기반으로 다양한 이미지를 창작했다. 디자이너는 이렇게 틸다가 만든 이미지와 패턴을 기반으로 제작한 의상을 패션 쇼에서 선보이는 방식으로 협업을 진행했다.

| 멀티모달 AI가 넘어야할 벽과 산
더 많은 멀티모달 AI가 등장하고, 더 많은 분야에서 인공 지능이 활약하면, 더 많은 것들이 가능해진다. 하지만 이러한 AI의 성장과 발전이 마냥 반가운 것은 아니다. 인공 지능은 말 그대로 사람의 지능을 모방하는 것이기 때문에 언제든지 오류가 생길 수 있고, 무엇 보다 그것을 사용하는 사람이 올바르지 않은 방향으로 악용하거나 남용하는 문제에서도 자유로울 수 없다.
예를 들어 달·이와 이매진 처럼 텍스트를 기반으로 이미지를 생성하는 멀티모달 AI는 사실 여러가지 문제점을 안고 있다. 이를 테면 악의적인 사용자가 음란물을 생성하거나 다른 사람의 사생활이나 초상권을 침해할 수 있다. 달·이의 경우는 이러한 문제가 발생하지 않도록 사실적인 얼굴이 포함된 사진이나 유명인의 초상을 만드는 것은 거부하도록 되어 있다.

하지만 앞으로 텍스트를 기반으로 이미지를 생성하는 인공지능은 봇물처럼 쏟아져 나올 텐데, 그렇게 세상에 나오는 멀티모달 AI가 이러한 문제에 대해 완벽하게 대응할 수 있을지는 장담할 수 없다. 특히 인공 지능을 개발하고 운영하는 사람이나, 이를 사용하는 사람이 모두 이러한 기본적인 원칙을 지켜야 한다.
이미 사회적으로 문제가 되고 있는 가짜 이미지나 영상에 대한 문제도 넘어야할 벽이다. 문자부터 시작해서 사진과 영상을 모두 사용하는 멀티모달 AI가 점점 더 많아지고 일상 생황에서 자연스럽게 접할 수 있게 되면, 누구나 쉽고 빠르게 간단한 문장만으로 원하는 사진을 만들거나, 동영상에 엉뚱한 사진을 합성할 수 있다.
인공 지능은 기본적으로 학습이라는 과정을 필요로 한다. 학습을 위해 많은 데이터가 준비되어야 하고, 수시로 업데이트된 데이터를 입력해 지능 수준이 향상되어야 한다. 하지만 학습 과정에서 제공되는 데이터에 오류가 있거나 특정 분야에 편중되어 있다면, 실제와는 다른 엉뚱한 결과를 출력하게 된다. 이는 모든 인공 지능이 태생적으로 가진 한계지만 멀티모달 AI처럼 더 다양한 정보를 다루게 되면 이런 위험성은 더욱 커진다.
또 하나 논란의 중심에 있는 것이 인공 지능이 생성한 결과물을 창작의 결과로 인정할 수 있는지, 그리고 이렇게 생성된 이미지에 대한 저작권을 인정할 수 있느냐의 문제다. 특히 텍스트 기반으로 이미지를 생성하는 인공 지능은 대부분 기존에 있는 사진이나 이미지를 기반으로 하기 때문에, 사람이 직접 창작했거나 다른 인공 지능이 만든 이미지 데이터가 있어야 하는데 이 부분에서도 저작권이 문제가 될 수 있다.
최근 달·이와 이매진처럼 텍스트를 이용해 이미지를 생성하는 인공지능인 미드저니(midjourney)을 활용해 만들어낸 이미지가 미국의 미술 공모전에서 1등을 하면서 뜨거운 논란이 일으킨 것이 대표적인 사례다. 미국의 게임디자이너가 미드저니를 이용해 제작한 ‘스페이스 오페라 극장’이라는 작품이 ‘디지털아트·디지털합성사진’ 부문에서 1등을 수상한 것이 문제의 발단이 됐다.
이 처럼 멀티모달 AI의 미래에는 앙지와 그늘이 모두 존재한다. 우리의 일상과 업무에서 만나게 될 멀티모달 AI가 시간이 지나면서 어떤 모습으로 성장하게 될 지 장담할 수는 없지만 그것이 바꾸어 놓을 우리의 삶과 생은 지금과는 다를 것이라는 것은 분명하다. 그래서 먼저 아는 것이 중요하고, 멀리 보는 것이 필요하다. 더 똑똑하고 재주 많은 인공 지능을 제대로 활용하려면, 인공지능을 결코 가질 수 없을 지혜로운 사람이 되어야 하지 않을까?
⧉ SKT의 음성인식 인공지능 서비스 NUGU 블로그에 제공한 콘텐츠 원문입니다.
'🅣•TREND•TECHNOLOGY > ARTIFICIAL INTELLIGENCE' 카테고리의 다른 글
| AI가 운전자 심전도로 졸음 인식...매스웍스, '웨이블릿 & 딥러닝' 툴박스 활용 (0) | 2023.01.30 |
|---|---|
| AI로 소매업 '손실 문제' 해결..엔비디아, AI 활용 도난 방지 애플리케이션 발표 (0) | 2023.01.17 |
| '바코드 없이 사진으로 구분'...아마존, AI 활용하는 아이템 인식 MMID 개발 중 (0) | 2022.12.14 |
| 언어 장벽 넘고, 실시간 번역까지 OK! ...기계 번역, 인공 지능으로 확장하고 진화한다 (0) | 2022.12.13 |
| 비즈니스용 이미지도 AI가 뚝딱!...디자인 플랫폼 캔바, 텍스트-이미지 AI 출시 (0) | 2022.11.14 |
| '언어 지원, 이미지 생성, 기후 변화 대응'...구글, 'AI가 기술을 확장하는 세 가지 방법' (0) | 2022.11.03 |
| AI가 만든 '스톡 이미지' 시대 열린다...셔터스톡, 오픈AI 이미지 생성기 API로 연동 (0) | 2022.11.02 |
| "당신의 '상상'은 비디오가 된다"...메타, 제너레이티브 AI '메이크 어 비디오' 공개 (0) | 2022.10.05 |



