
'음성을 인식한다'는 하나의 문장에는 많은 의미가 들어가 있다. 사람 목소리를 알아듣고, 어떤 언어를 사용하는지 알 수 있어야 하고, 말하는 내용을 이해할 수 있어야 하며, 때로는 맥락까지 간파해야 한다. 결국 인공 지능이 '음성을 인식할 수 있다'는 것은, 궁극적으로 '인간 수준'의 정확성과 완벽함을 가진 언어 능력을 가지고 있어야 한다.
오픈AI(OpeanAI)가 공개한 위스퍼(Whisper)는 바로 그런 수준의 음성 인식 수준을 갖는 인공 지능을 개발하기 위한 오픈 소스 기반 다국어 음성 인식 아키텍처다. 음성 인식을 통한 유용한 애플리케이션을 구축하고, 강력한 음성 처리를 위한 연구에 활용할 수 있는 모델 및 추론 코드를 깃허브(github)를 통해 공개했다.
인공 지능 기반 음성 인식은 이미 다양한 형태로 상용화되어 있고, 다양한 연구 기관과 기업에서 고성능 음성 인식 시스템을 개발하고, 이를 활용한 다양한 상품과 서비스가 나와있다. 물론 이러한 인공 지능을 활용한 음성 인식 기술의 진화는 여전히 현재 진행형이고, 다양한 알고리즘과 아키텍처를 통해 계속해서 발전을 거듭하고 있다.
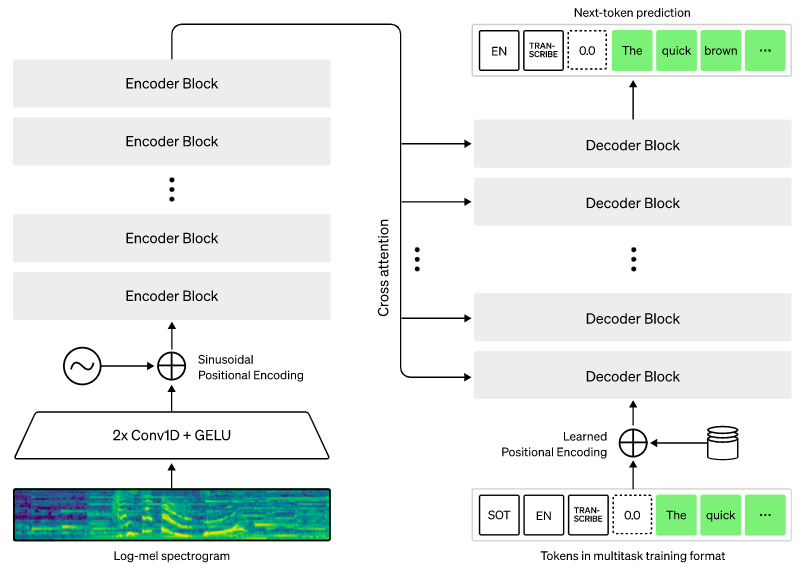
이러한 상품이나 시스템과 차별화되는 위스퍼의 특징은 웹에서 수집한 68만 시간 분량의 방대한 자료를 활용해, 다국어 및 다중 작업(multitask supervised data) 데이터에 대해 훈련한 자동 음성 인식(ASR;Automatic Speech Recognition) 시스템이라는 점이다. 크고 다양한 방대한 데이터 세트를 활용해 학습시킨 덕분에, 액센트나 배경 소음 등 다양한 요소까지 고려한 정확한 음성 인식이 가능하다는 것이 오픈AI의 설명이다.
오픈AI는 "위스퍼는 크고 다양한 데이터 세트에 대해 교육을 받았고, 특정 데이터 세트에 대해 미세 조정되지 않았기 때문에, 음성 인식에서 유명한 경쟁 벤치마크인 리브리스피치(LibriSpeech) 전문 모델을 능가하지는 않는다. 그러나 다양한 데이터 세트에서 위스퍼의 제로샷 성능을 측정하면, 훨씬 더 강력하고 이러한 모델보다 오류가 50% 더 적다"고 밝혔다.
오픈AI의 위스퍼 블로그에는 이러한 위스퍼에 대한 아키텍처와 훈련 방법 등이 소개되어 있다. 특히 실제 웹에서 수집한 데이터를 영어로 전사(transcription)한 세 가지 샘플을 확인할 수 있다. 케이팝(K-Pop) 예제에서는 윤하의 오르트구름이라는 노래 가사를 영어로, 프렌치(French)는 프랑스어로 설명하는 위스퍼에 대한 설명을 영어로, 액센트는 억양이 강한 영어를 이해하고 영어 텍스트로 옮긴 내용을 확인할 수 있다.
위스퍼에 대한 자세한 자료는 블로그를 방문하면 무료로 다운로드 받을 수 있다. 블로그에는 PDF 형식의 논문(Paper), 오픈 소스로 공개된 코드(CODE)와 모델 카드(MODEL CARD)는 깃허브 링크를 통해 확인할 수 있다. 위스퍼는 소음이 많이 들어간 다양한 광범위한 데이터를 통해 훈련된 만큼, 없는 단어를 전사하거나 언어에 따른 인식 편차 등 여러가지 오류가 있을 수 있다.
⧉ Syndicated to WWW.CIOKOREA.COM
'🅣•TREND•TECHNOLOGY > ARTIFICIAL INTELLIGENCE' 카테고리의 다른 글
| 비즈니스용 이미지도 AI가 뚝딱!...디자인 플랫폼 캔바, 텍스트-이미지 AI 출시 (0) | 2022.11.14 |
|---|---|
| '언어 지원, 이미지 생성, 기후 변화 대응'...구글, 'AI가 기술을 확장하는 세 가지 방법' (0) | 2022.11.03 |
| AI가 만든 '스톡 이미지' 시대 열린다...셔터스톡, 오픈AI 이미지 생성기 API로 연동 (0) | 2022.11.02 |
| "당신의 '상상'은 비디오가 된다"...메타, 제너레이티브 AI '메이크 어 비디오' 공개 (0) | 2022.10.05 |
| 직접 만든 콘텐츠에 AI 성우 목소리를...머프, 사람만큼 자연스러운 AI 음성 라이브러리 (0) | 2022.09.22 |
| 아바타 제작도 클라우드 AI로 간편하게...엔비디아, '옴니버스 ACE' 발표 (0) | 2022.08.11 |
| 100만 명에게 AI 이미지 생성 제공...오픈AI, DALL·E 2 베타 출시 (0) | 2022.07.23 |
| 그래프코어, 슈퍼컴 수준의 IPU 성능 달성...MLPerf 벤치마크 결과 공개 (0) | 2021.07.08 |



